Attention to Transformers
Transformers are popular nowadays. They are becoming state of the art in all domains since they first debuted in the paper “Attention is All You Need” by Vaswani et al. [1]. Although we just call them “transformer”, it is the attention mechanism as we first saw in the paper “Neural machine translation by jointly learning to align and translate” by Bahdanau et al. [2]. In this article, I’d like to explain what is attention mechanism, how transformers are effective in what they are doing, and the latest advancements in transformers.
Let’s start with the attention mechanism. In the original paper, attention mechanism defined as the probability (alpha_t) of generating expected output (y_t) and deciding next state (s_t) of an embedding (h_t) w.r.t state at previous time step (s_{t-1}) . In other words, out of all current embeddings, how much attention should we pay for a specific one for generating expected output while moving onto the next state.
Although the original attention paper was on the NLP domain, the same method applies for computer vision tasks, too. Indeed, the first paper that is using the same method is Xu et al.’s “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention” [3]. I hear some are saying Mnih et al.’s famous paper “Recurrent Models of Visual Attention” [4] and Ba et al.’s “Multiple Object Recognition with Visual Attention” [5] are also mentioning about attention, but they have a different method, which is now we call “hard-attention” as described in Xu et al.
Behold The Transformer!
Now we know, either in NLP or CV or multi-modal setup, attention is used to compute the importance of an input within the context of the current time step. Furthermore, in its simple form, the attention mechanism is put between encoder and decoder in sequence modeling. So comes the breakthrough, can we get rid of this recurrence of the encoder-attention-decoder spiral?
So the answer to that question is “the transformer”. Without using an encoder-decoder recurrent network, the transformer architecture uses only the attention mechanism (hence the name of the paper). But why and how is this architecture more efficient than the original attention-based encoder-decoder recurrent network model?
Why It Is Efficient?
The secret of the success of the transformer is relying on the self-attention. The original paper gives us three reasons for why they used self-attention:
- Reducing the computational complexity
- Maximizing the parallelization of operations
- Maximizing the path length between long-range dependencies.
To understand what these three items mean, we should take a look at self-attention.
Self-attention
As the name implies, self-attention is the attention among input tokens. Let say, you have an input sentence, “Today the weather is rainy, so I bring my umbrella”, when you tokenize this sentence you’ll get a set of words X =(“Today”, “the”, “weather”, “is”, “rainy”, “so”, “I”, “bring”, “my”, “umbrella”). Self-attention will give you a 10x10 matrix that shows the importance of each pair of this set.

Note that, this is a set, and the order of items in a set is not important! So the original paper also brings in another technique to consider the position of a token. This technique is called positional encoding, which we will cover in a bit…
A Big Oh!
We all familiar with computational complexity, and of course the famous big O. So self-attention has a constant O(1) time in sequential operations where recurrent layers have O(n) where n is the length of the token set X (in our example it is 10). In layman’s terms, self-attention is faster than recurrent layers (for a reasonable number of sequence length).
Remember Remember The Transformer
Aside from being effective in computational complexity, the transformer can handle longer dependencies more efficiently than recurrent models. Recurrent models should traverse the entire sequence in order which self-attention does not maintain, so dependency check can be done between any pair in O(1) constant time.
How It Works?
If you are not felt asleep until now, the fun part is about to begin. Let’s see the general architecture from the original paper:

Positional Embedding
The first thing the transformer does is to compute positional embeddings (PE) of the input. Remember, the transformer tokenized the input which does not keep the order. So we need to put that position information back. The paper does this smartly by using sine and cosine functions where the frequency is tuned by position and index of dimension.
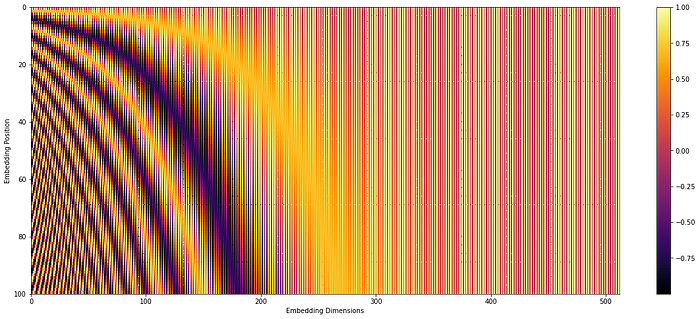
Query, Key, and Value
The transformer computes Query, Key, and Value vector from the input. The intuition here is analogous to a search engine. We enter a query, our query is aligned with keys, and the search engine relates our query-key matching with values. Here, our input embedding is queried against itself. So, for each input embedding, we compute query vector, key vector, and value vector. In practice, we form all vectors at once, so we have a Q matrix, K matrix, and V matrix. Then, we score how our queries are aligned with keys (with normalization factor, of course). Then we pass scores through a softmax to boost up relevant scores while pushing down irrelevant. Then we compute how much we should pay attention to values. Remember, Q, K, and V are all generated from the input itself (i.e. self-attention). Therefore, the transformer learns the weight matrices, W_q, W_k, and W_v that we are using to generate Q, K, and V.
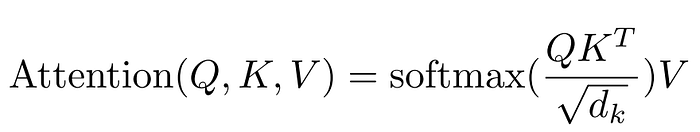
Multi-head Attention
In practice, applying attention to all input embeddings at once averages on all positions. Instead, we can apply attention in parallel to subspaces, which might attend to different representations in subspaces. In the paper, this parallelism is 8, so instead of computing attention in all 512 dimensions, it is applied to eight different 64 sub-dimensions.

Wrapping Up
So, without using recurrent units, and without trying to maintain the order of input embeddings, we have a much simpler architecture using only an attention mechanism and can maintain longer dependencies among embeddings.
Transformers Roll Out!
If I say transformer paper disrupted the entire AI/ML community, I wouldn’t exaggerate. We are now seeing an entire line of work based on transformers, not only in the original NLP domain but also in the computer vision domain. I’d like to list a couple of recent popular works that came out recently:
- In the NLP domain, GPT-2 [6], BERT [7], and, lately, GPT-3 [8]became state of the art. No need to mention how popular they became.
- In the computer vision domain, Image Transformer [9] and recently Vision Transformer [10] are worth mentioning.
Note: this is far from a comprehensive list, and I skipped a ton of great papers.
Conclusion
In conclusion, I’m sure that we’ll see a lot more work will come out based on transformers. So, if you are interested in moving the needle of state of the art, attend to self-attention and the transformer.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., Polosukhin, I., Kaiser, L., Polosukhin, I., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems, 2017-Decem, 5999–6009. https://arxiv.org/pdf/1706.03762.pdf
[2] Bahdanau, D., Cho, K. H., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. ArXiv E-Prints, arXiv:1409.0473.
[3] Xu, K., Ba, J. L., Kiros, R., Cho, K., Courville, A. C., Salakhutdinov, R., Zemel, R. S., & Bengio, Y. (2015). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. CoRR, abs/1502.0, 2048–2057. http://arxiv.org/abs/1502.03044
[4] Mnih, V., Heess, N., Graves, A., & kavukcuoglu, K. (2014). Recurrent models of visual attention. Advances in Neural Information Processing Systems, 3(January), 2204–2212.
[5] Ba, J. L., Mnih, V., & Kavukcuoglu, K. (2015). Multiple object recognition with visual attention. 3rd International Conference on Learning Representations, ICLR 2015 — Conference Track Proceedings, 1–10. http://arxiv.org/abs/1412.7755
[6] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners.
[7] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. https://doi.org/10.18653/v1/N19-1423
[8] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language models are few-shot learners. In arXiv. arXiv. http://arxiv.org/abs/2005.14165
[9] Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., & Tran, D. (2018). Image transformer. 35th International Conference on Machine Learning, ICML 2018, 9, 6453–6462. http://arxiv.org/abs/1802.05751
[10] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. http://arxiv.org/abs/2010.11929
